Semantic Models That Run: From CSV to Context-Rich Linked Data. Powered by

A live, standards-based transformation pipeline.
Powered by a real-time domain model in Jargon.
No hardcoded rules.
No hidden scripts.
Just declarative mapping, semantic precision, and end-to-end transparency.
A public demonstration - submitted to the OMG Semantic Augmentation Challenge 2025.
What if meaning could be added to raw data — and made executable, not just descriptive?
CSV isn’t just flat - it’s fragile. No datatypes. No relationships. No identifiers. No context. Every value is just a string - and every integration relies on humans guessing what columns mean. That’s the semantic gap this challenge asked us to close.
The challenge asked for a mapping format - a way to describe how columns relate to semantics. This submission includes just that - mapping that is: readable, declarative, and aligned to real-world vocabularies like FIBO, GeoSPARQL, and schema.org. BUT the mapping is just one artefact. What you’ll see here is a fully working system - one that transforms CSV into structured JSON, validates it with JSON Schema, expands it with JSON-LD, and outputs RDF - all with no custom code.
This demo shows how semantic models can lift those flat structures into context-rich, machine-readable JSON-LD, using declarative mappings and live validation, all driven by a single source of truth.
SERVTYPE_DESC,ADDRESS,CITY,COUNTY,STALP,ZIP
"FULL SERVICE - BRICK AND MORTAR","18001 Saint Rose Rd", "Breese", "Clinton", "IL", "62230"
{
"https://banks.data.fdic.gov/ontology/hasServiceType": {
"@type": "http://www.w3.org/2001/XMLSchema#string",
"@value": "FULL SERVICE - BRICK AND MORTAR",
},
"fdic:address": [
{
"https://schema.org/addressLocality": [
{
"@type": "http://www.w3.org/2001/XMLSchema#string",
"@value": "Breese"
}
],
"fdic:county": [
{
"@type": "http://www.w3.org/2001/XMLSchema#string",
"@value": "Clinton"
}
],
"https://schema.org/addressRegion": [
{
"@type": "http://www.w3.org/2001/XMLSchema#string",
"@value": "IL"
}
],
"https://schema.org/streetAddress": [
{
"@type": "http://www.w3.org/2001/XMLSchema#string",
"@value": "18001 Saint Rose Rd"
}
],
"https://schema.org/postalCode": [
{
"@type": "http://www.w3.org/2001/XMLSchema#string",
"@value": "62230"
}
]
}
}
At the centre of this solution is a live Jargon model. It isn’t a static diagram. It’s the working source that drives every transformation, validation, and semantic expansion in this demo. Every step is traceable, standards-aligned, and running in real time.
The process begins with a simple CSV file. A declarative mapping - aligned to the domain model - transforms that input into structured JSON. The result is then validated using JSON Schema, and expanded with JSON-LD to include globally meaningful identifiers and types - all derived from the same model.
The process is driven by The Model that Drives Everything. The only other input is the competition's CSV file. The transformation pipeline proceeds through these stages:
The model also includes vocabularies such as GEOSPARQL, schema.org, and selected elements of FIBO. These were transformed from published RDF sources into reusable domain models inside Jargon. Some were imported directly. Others, like FIBO, use cherry-picked IRIs.
Once imported, these behave like native domains: composable, semantic, and runnable - without OWL reasoning or traditional ontology tooling.
This submission isn’t a prototype or wireframe. It’s a running, standards-based implementation.
Every step is live. Every artifact is generated directly from the model.
Traditional modeling tools focus on completeness or theoretical rigor. But they often stop short of producing outputs that real systems can use. This results in models which may look precise, but are still reliant on brittle scripts or manual interpretation.
This demo takes a different approach. The Jargon model powers everything you see.
JSON Schema, OpenAPI, JSON-LD, RDF, and validation logic all come from a single, traceable source of truth.
No translation layer. No handoffs. No drift.
This is modeling that runs. Not simulation. Not documentation. A living contract between data, systems, and semantics - in real time.
This demonstration uses W3C and industry standards from start to finish:
Jargon makes these standards usable without custom code, scripts, or hand-built vocabularies.
This isn’t a diagram. It’s the source of truth — and the engine behind everything you’re about to see.
And Jargon is the engine behind the model:
Every transformation in this demo starts here and stays aligned throughout. No manual edits. No duplication. No drift.
Just rows and columns for now — but it’s the foundation we’ll transform into something semantically rich.
This is the raw data used in the challenge: a flat CSV file with basic policyholder and provider details. Other than the domain model, this is the only input required.
Note:
This demo runs on a 100-row sample of the official FDIC dataset to ensure instant responsiveness in the browser.
The full 80,000-row dataset has been processed using the exact same model and mapping — with no code changes.
The resulting expanded JSON-LD output (over 450MB) is included in the submission ZIP as evidence of successful full-scale execution.
The bridge between model and data — generated, not hand-written, and entirely traceable.
This mapping shows how each CSV column connects to elements in the domain model. It wasn’t written by hand. Jargon generated it automatically based on the model. Each field you see is derived from a class or property in that model.
[csv.columnName] annotation in the model.
Jargon does the rest:
Generating a plain JSON mapping file - inspired by JSONPath, but tailored for CSV-to-JSON transformation.
Loading...Here’s where the model proves itself. One click turns tabular data into structured content - ready for meaning.
This is where all of the pieces come together. Where the magic happens.
You’ve seen the model and its mapping. Now you can run the transformation.
The button below takes the CSV input and applies the mapping generated by Jargon. It’s not handcrafted logic. It’s model-driven structure running in real time.
This transformation is live and reactive. Modify the CSV above and rerun this step to see updated results immediately.
Click "Transform" to generate JSON from the CSV input and mapping above.We check the shape of the data — and ensure it matches the model’s expectations exactly.
The specific structure of the transformed JSON isn’t what matters — it’s that the structure we use is known, descriptive, and enforceable. Without that, we can’t reliably apply meaning or process the data. JSON Schema gives us that guarantee.
The schema shown here wasn’t written by hand. Jargon generated it automatically from The Model that Drives Everything — the single source of truth for this entire pipeline. You can verify this by opening the dropdown in the embedded model above - the schema matches exactly.
Jargon doesn’t just help you design models. It makes sure those designs are enforced, from transformation to validation and beyond.
A quick note on the source data: the provided CSV contained a number of structural inconsistencies — the same logical columns represented in different ways (for example, 1 vs TRUE, date serials vs date strings), and even a repeated header row midway through the file.
I don’t know the provenance of the file, and it may represent a heroic effort to gather data from diverse contributors. But this is precisely why structural validation matters. A standards-based JSON Schema can catch these inconsistencies early — helping teams avoid costly surprises downstream.
Loading...Click "Validate" to check the generated JSON aligns with the JSON Schema.
Now every field gains meaning. The data isn’t just structured — it’s semantically explicit.
Even richly structured JSON isn’t enough on its own. Machines still need help understanding what the data means, not just how it's shaped.
This step uses the @context generated by Jargon to expand each field into a fully qualified semantic identifier.
It’s how we turn column names into machine-readable references that align with shared vocabularies.
Loading...Show a mapping of columns in a machine-readable and processable format to common and citable resources.
That’s exactly what this step does.
Using a model-generated @context, we resolve fields like:
dateEstablished → schema:foundingDatebranchAddress → schema:streetAddressnumOffices → xsd:integerThis isn’t just prettier JSON. It’s enriched, contextual data - ready for validation, integration, querying, or reasoning by any Linked Data system.
The result below shows the fully expanded form in both JSON-LD and RDF (Turtle/N-Quads) views:
Click "Expand" to see expanded JSON-LD.Click "Expand" to see RDF/N-Quads.It’s not enough to say the data is enriched — this proves it was enriched correctly.
Once data has been expanded into its semantic form using JSON-LD, the question remains: "was it expanded correctly?" Were the right URIs applied? The right structure used? The right context referenced?
Jargon generates a second-layer validation schema — one that operates not on the raw data, but on the expanded JSON-LD graph. This schema confirms that:
This acts as a contract: not just that the data is present, but that it is semantically aligned and trustworthy — without relying on SHACL or OWL.
providerId → schema:providerIdpolicyType → omg2:policyTypeLoading...Click "Validate Semantics" to check the expanded JSON contains the expected semantic mappings.
This is where the semantics become portable — described in RDF, aligned to standards, and always in sync with the model.
The Jargon models aren't only describing structure - they define meaning. This section shows the machine-readable vocabulary generated automatically from the same domain model used for transformation and validation.
The output includes both a JSON-LD graph and a RDF (N-Quads), declaring every class and property with types, labels, domains, and ranges.
It uses standard ontologies like rdfs, owl, xsd, and schema.org.
Because the vocabulary comes from the same source as the schema and mappings, it stays aligned. No duplication. No drift.
Loading...Click "Expand" to see RDF/N-Quads.Data evolves. Models drift. This shows how Jargon manages semantic change without losing control.
As datasets evolve, metadata can easily fall out of sync. Columns change. Definitions shift. Without versioning, even well-modeled data can become misleading.
This demonstration shows a snapshot in time, but the platform behind it - Jargon - is designed for ongoing change:
Jargon acts as a semantic version control system. Keeping metadata aligned as the meaning of data evolves.
These screenshots are taken from the UNTP Core domain, an active project used by the United Nations Transparency Protocol team. They show how Jargon supports versioning, collaboration, and semantic reuse in real-world modeling use case.
Version history for a published model
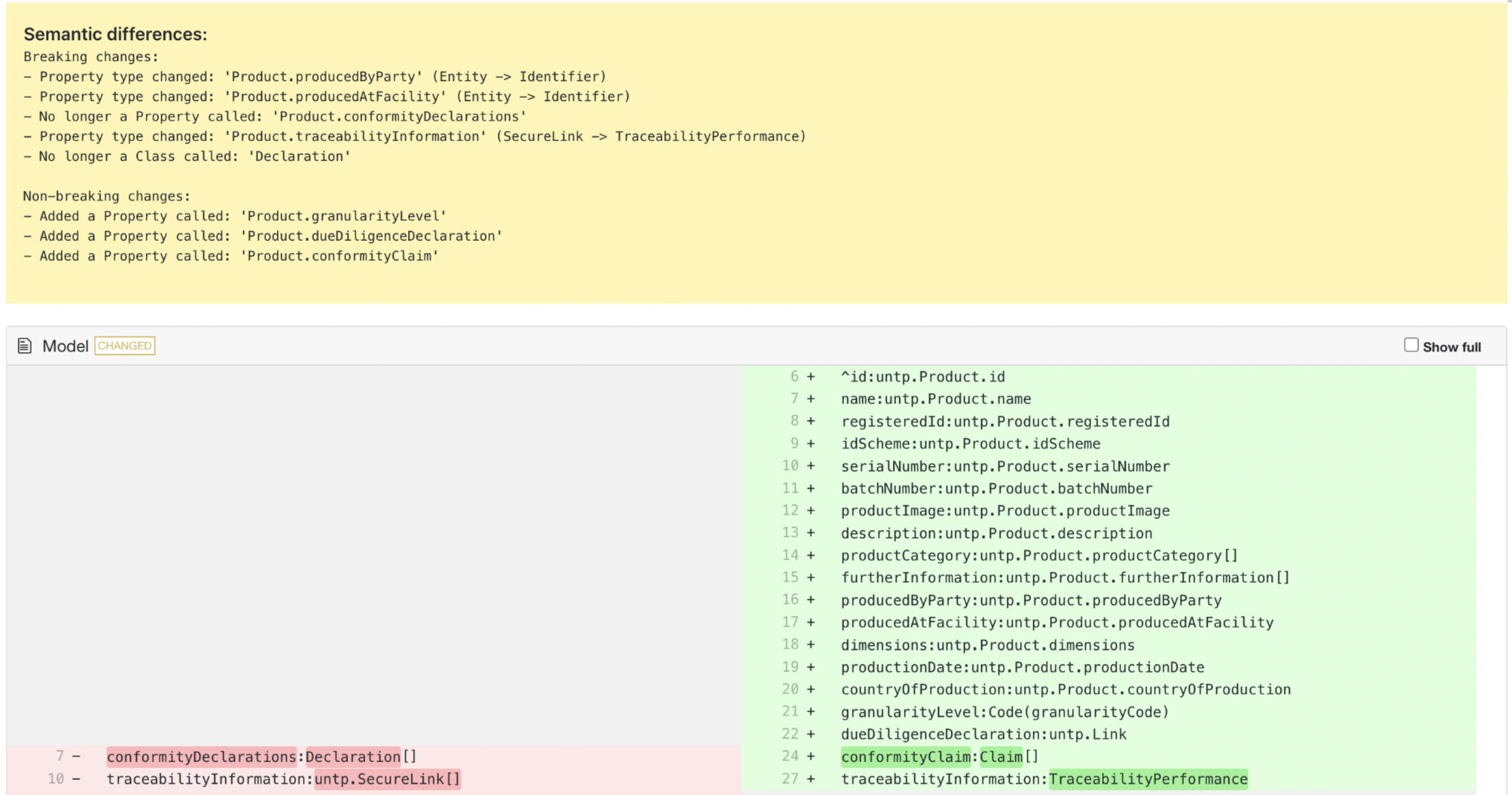
Semantic diff and model change viewer
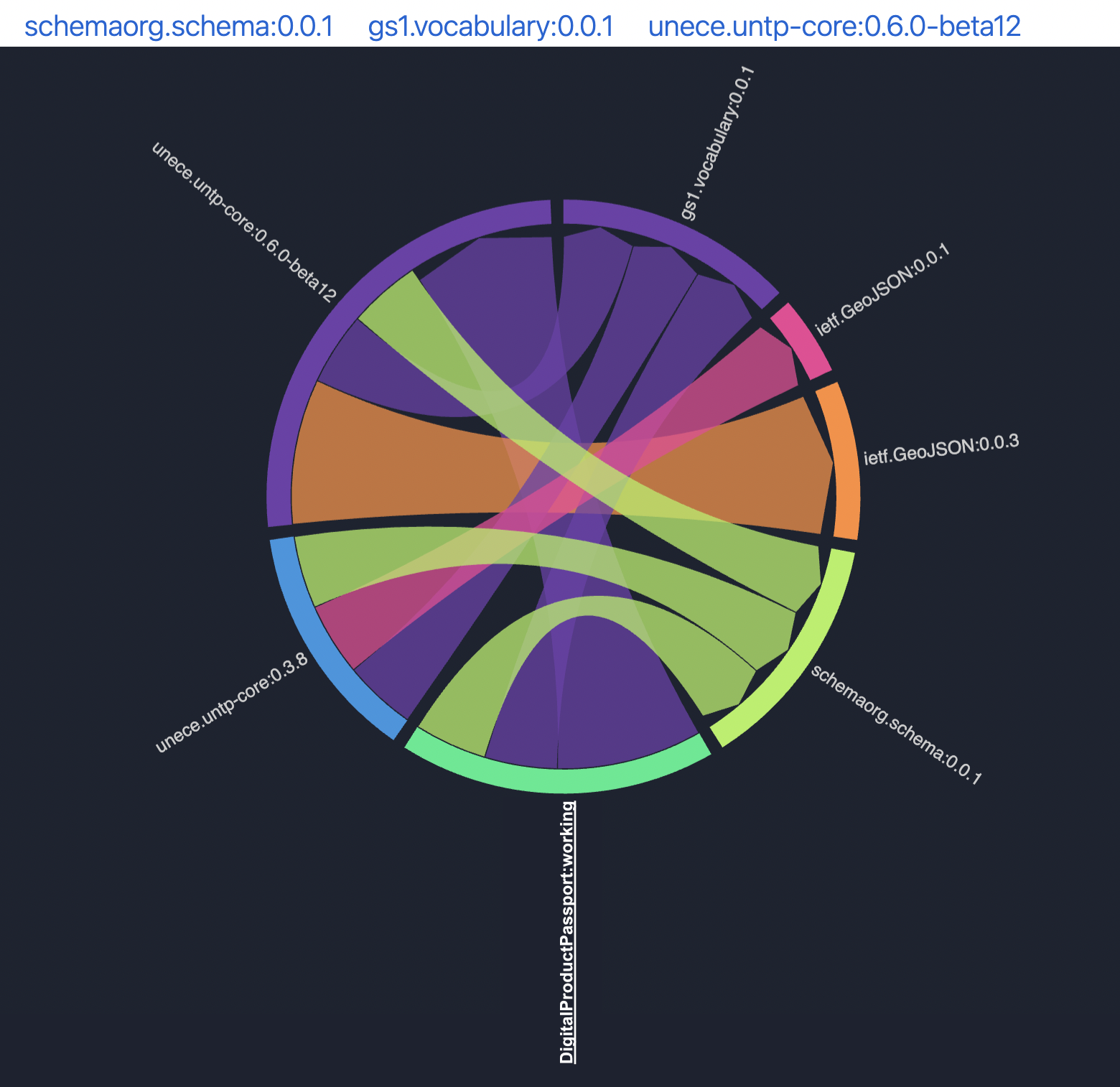
Visual dependency graph for reuse and alignment
Want to explore it live? Visit the UNTP Core domain to see how shared vocabularies are managed across multiple projects.
Not just a one-off demo — a repeatable system where models, mappings, and semantics stay in sync
This approach isn’t just about one dataset. It's about a repeatable, model-driven pipeline that keeps everything aligned:
mapping.jsonschema.json for validation@context for semanticsYes, Jargon even generates API designs. The same model that structures and enriches the data also powers real-world integration.
All of this is possible because of the underlying model. But what if you wanted to build a real system on top of it?
This same model can:
This isn’t just about mapping. It’s infrastructure built on models. The outputs are consistent, governed, and ready to run.
You’ve just walked through a complete semantic transformation - from a flat CSV file to structured, machine-readable JSON-LD.
What makes it different is how it was done:
@context, not handwritten rules.Every artifact - the mapping, schema, context, and output - came from a single source of truth. Nothing is stitched together. Nothing can go out of sync.
This isn’t just format conversion. It’s semantics that run. And it shows how models can become real, working parts of systems - with immediate feedback and no ambiguity.
For years, we built models that were too complicated for people to use - and still not useful to machines.
This demonstration flips that. The model is simple enough to understand, and structured enough to run.
It doesn’t replace semantic modeling - it builds on it and applies it where it matters most.
By making semantics meaningful for machines.
By making them Run.
This demonstration was built to answer a technical challenge, which it did by applying structured modeling — but the unspoken, deeper challenge behind the competition is a strategic one.
We’ve spent decades drawing models, publishing standards, and writing specs. But somewhere along the way, modeling lost its footing. It became too abstract for developers, too brittle for change, and too removed from the systems it was meant to serve.
The results are clear:
This approach shows another way:
No triple store. No OWL. No SHACL.
Just a single, live model — powering every transformation, validation, and API contract.
Executable. Traceable. Governable.
It looks like modeling.
It feels like modeling.
But it runs.
This isn’t a reinvention of UML.
It’s a quiet demonstration of what modeling could have become — and maybe still can.
If this feels familiar, like something you once tried to do but didn’t quite land, that’s because it is.
I built it to show that it’s possible. Not in theory. In practice. And this submission is the proof.
If the time feels right to try again — I’d welcome the conversation.
alastair [at] jargon [dot] sh
